En el post anterior hablábamos sobre la arquitectura de Apache Spark, una de las mejores herramientas de Big Data y procesamiento de datos junto con Apache Kafka, cuya arquitectura desvelaremos a continuación.
¿Qué es Apache Kafka?
Kafka es un sistema distribuido de mensajería de publicación y suscripción, donde los temas se replican y, que mantiene canales de mensajes en temas. Los productores escriben datos a los temas y los consumidores leen temas. Apache Kafka es una plataforma distribuida de streaming de eventos. Inicialmente fue concebida como un sistema de mensajería basado en colas, en la actualidad Apache Kafka es más bien una abstracción de un commit log distribuido.
Los mensajes pueden ser usados para almacenar cualquier objeto en cualquier formato. Cuando se consume un tema, es posible configurar un grupo de consumidores con múltiples consumidores. Cada consumidor lee los mensajes de un subconjunto único de particiones en cada tema al que se suscriban y todos los mensajes con la misma llave llegan al mismo consumidor. Kafka es capaz de soportar y retener grandes cantidades de datos con muy poca carga.
¿Qué puede hacer Apache Kafka?
- Mensajería (PUBLISH/SUBSCRIBE): sistema de mensajería de tipo publish-subscribe, con un sistema de registro de tipo inmutable.
- Almacenamiento (STORE): Commit log distribuido e inmutable. Actúa como fuente de conocimiento.
- PROCESS: permite manipular los datos según llegan (streaming)
Estos son algunos de los conceptos que maneja Apache Kakfa
- Zookeeper: es el servicio de orquestación de nodos de tipo bróker de Apache Kafka. Es importante que en un clúster de servidores Kafka, el número de servidores sea impares, siendo el mínimo recomendable tres.

- Topics: se traducen como temas. En esencia son las colas o buses a los cuales se publican/suscriben datos.
- Partitions: Son la forma en la que un topic escala dentro de Apache Kafka. Es decir, equilibra la carga de mensajes(Datos) dentro del clúster.
¿Cómo escoger el número de partitions?
Hay tres variables que se necesitan saber de antemano a la hora de determinar el número de partitions dentro del clúster de Kafka:
- Ancho de banda deseado
- Ancho de banda máximo por partition
- Ancho de banda disponible

Como norma general, se debería probar siempre con un número alto de partitions e ir variando esta variable en función de las necesidades deseadas.
- Publishers: Siempre se usará Apache Kafka escribiendo desde un producer, un lector que consuma esos datos (suscriber), o una aplicación que sirva los dos roles.
Los mensajes en Apache Kafka son de tipo Key – Value. Las keys cumplen dos condiciones:
- Son información que se almacena con el mensaje
- Ayudan a decidir a qué partition irá el mensaje.
- Consumers: Los consumidores en Apache Kafka son siempre parte de lo que se denomina ‘consumer.group’. Cuando muchos consumers se suscriben a un topic y pertenecen a un mismo ‘consumer.group’, cada consumer de ese grupo recibirá mensajes de diferentes subsets de las particiones del topic o tema.
Kafka Streams
Primero recordemos qué es un stream de datos. Data Stream, Event Stream, Streaming Data… son abstracciones que representan un conjunto de datos que no tienen límite. Esto quiere decir que su naturaleza es infinita y que está en constante crecimiento. No tiene límite porque, mientras transcurre el tiempo, nuevos mensajes pueden ir llegando.
Además de tener una naturaleza sin límites:
- Los streams son ordenados: se sabe qué eventos ocurren antes que otros.
- Registros inmutables: los eventos, cuando ocurren, no pueden ser modificados.
- Son reproducibles: permiten corregir errores, probar nuevos métodos de análisis, realizar auditorías…
El stream processing es un paradigma de programación. Existen varias arquitecturas:
- Request-response: el de menos latencia. Es un paradigma bloqueante.
- Batch processing: es el que más latencia y ancho de banda ofrece de todos.
- Stream processing: opción no-bloqueante. Es una evolución del request – response.
Patrones de diseño en Stream Processing
- Single-event processing: Es el patrón más básico, procesa cada evento de forma aislada. También se conoce por el nombre de patrón map/filter, que a su vez está basado en el patrón Map/Reduce.
En este patrón, la aplicación de Stream Processing consume eventos del stream, modificando el evento, y luego produce el evento en otro stream.
- Processing with local state: Para aplicaciones que agregan información, especialmente aquellas que agrega datos en procesamiento dentro de ventanas de tiempo específicas.
Este tipo de agregación necesita mantener un estado del stream. En este tipo de patrones se deben tener en cuenta:
- Uso de memoria
- Persistencia
- Rebalanceo
- Multiphase processing / repartitioning: Un stream processing que tiene que pasar por varias fases. Muy similar a Map Reduce.
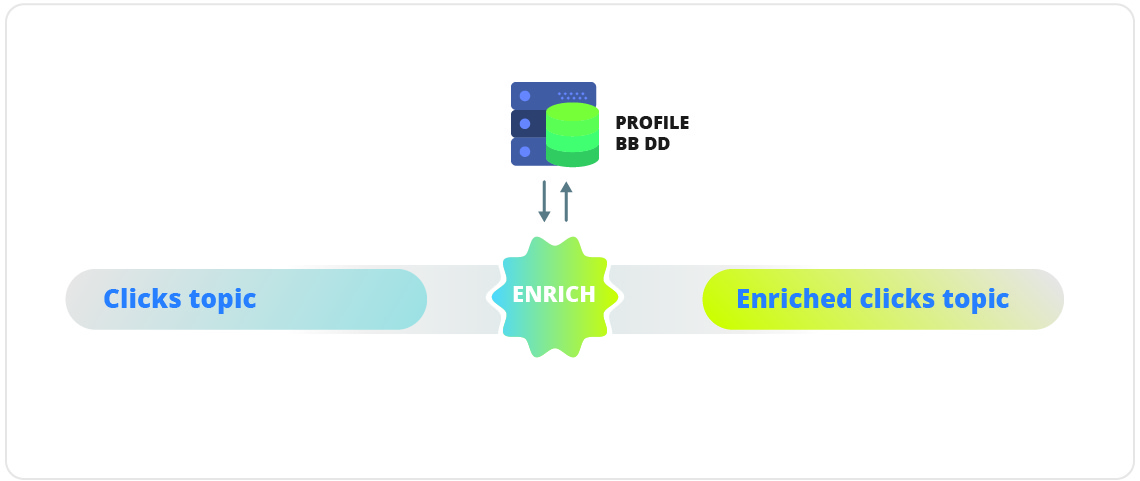
- Processing with External Lookup (Stream-Table Join): Cundo el Stream Processing necesita información con datos externos al Stream. Se trata de un proceso en el que el dato se enriquece con fuentes de datos externas.
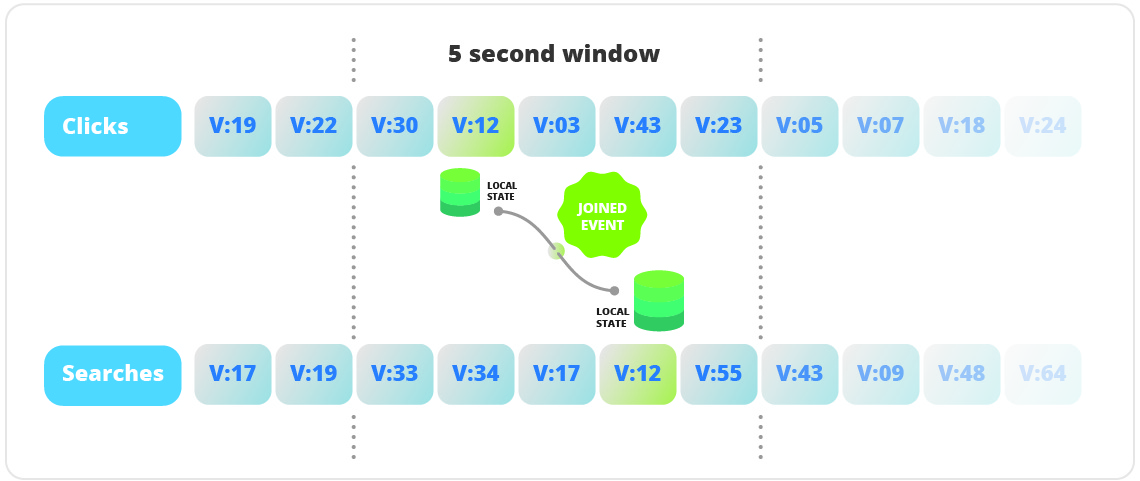
- Streaming Join: Cuando quieres o necesitas unir dos Stream Events. Podrías hacerlo con tablas, pero no tendrías el histórico de los streams.
- Out-Of-Secuence Events: Para manejar eventos que llegan ‘fuera de tiempo’. Muy útiles para dispositivos IOT.
- Reprocessing: Este patrón tiene dos variantes:
- De mejora: mejora de proceso en las aplicaciones stream processing
- De corrección: corrige algún fallo existente en la aplicación stream processing
Casos de éxito. ¿Quiénes utilizan estas tecnologías?
Kafka es utilizado actualmente por muchas compañías en procesos comerciales que involucran grandes cantidades de datos. Es capaz de escalar casi linealmente miles de millones o billones de mensajes. Entre ellos:
Tinder
Esta aplicación de citas aprovecha Kafka para múltiples propósitos comerciales, como por ejemplo, analítica, recomendaciones, notificaciones, geoposicionamiento, etc.
Tinder envía ~86B eventos por día (~1M de eventos/segundo), lo que supone más de 40 TB de datos / día. En este sentido, Kafka les permitió ahorrar más del 90% de rentabilidad en comparación con SQS / Kinesis.
Información presentada en Kafka Summit 2018 (Video en el sitio web de Confluent)
Pinterest tiene 200 millones de usuarios activos cada mes. Se generan más de 100 billones de pines creados por la gente que guarda imágenes y se buscan más de 2B de ideas mensualmente.
Kafka Streams se utiliza para indexar contenido, recomendaciones, detección de spam y, lo más importante, para cálculos de presupuestos de anuncios en tiempo real.
En este video puedes ver cómo Pinterest aprovecha el procesamiento de Kafka en el sitio web de Confluent.
Uber
Uber requiere mucho procesamiento en tiempo real. Manejan billones de mensajes y decenas de miles de temas.
Esta cantidad da como resultado un volumen de datos calculado en petabytes. Las capacidades de procesamiento por lotes se utilizan para lograr un mejor rendimiento.
Muchos procesos se modelan utilizando Kafka Streams, incluso los más importantes, como la búsqueda y relación entre clientes y conductores.
Enlace al vídeo: How Uber scaled its Real Time Infrastructure to Trillion events per day
Netflix
Netflix aprovecha los clústeres Kafka de múltiples clústeres manejando billones de mensajes por día. Netflix ha optado por usar dos réplicas por partición mejorando la disponibilidad pero puede causar una pérdida de datos, para solucionar este problema creó su propia herramienta de detección de rastreo de datos perdidos Inca , que puede detectar datos perdidos.
Para conocer más sobre Inca, eche un vistazo a la publicación de blog de Netflix .
Apache Kafka se origina en LinkedIn para resolver sus desafíos con sistemas relacionados con el monitoreo y seguimiento de la actividad del usuario. Actualmente, LinkedIn maneja 7 billones de mensajes por día, divididos en 100 000 temas, 7 M particiones, almacenados en más de 4000 runners.
La información más reciente sobre LinkedIn y cómo aprovechan Kafka se puede encontrar en la publicación del blog «Cómo LinkedIn personaliza Apache Kafka para 7 billones de mensajes por día».
Artículo en colaboración con nuestro compañero Sergio Sánchez de Ipglobal.
